
гҖҖгҖҖ12жңҲ3ж—ҘпјҢдёӯеӨ®ж°‘ж—ҸеӨ§еӯҰ56еҲӣеӯөеҢ–йЎ№зӣ®еӨ§еӯҰз”ҹеҲӣдёҡеӣўйҳҹ——е·ЁзҘһдәәе·ҘжҷәиғҪ科жҠҖпјҢеҸ‘еёғе…ЁзҗғйҰ–еҘ—и—Ҹж–ҮжүӢеҶҷдҪ“ж•°еӯ—ж•°жҚ®йӣҶTibetanMNISTпјҢ并еңЁеӣҪеҶ…йўҶе…Ҳзҡ„ж•°жҚ®з§‘еӯҰе№іеҸ°з§‘иөӣзҪ‘зӢ¬е®¶йҰ–еҸ‘гҖӮиҝҷдёӘеӯҰз”ҹеҲӣж–°еӣўйҳҹжӣҫдәҺд»Ҡе№ҙ6жңҲиў«иҜ„дёә“еҢ—дә¬ең°еҢәй«ҳж Ўдјҳз§ҖеӨ§еӯҰз”ҹеҲӣдёҡеӣўйҳҹ”гҖӮ
еӣҫдёәTibetanMNISTзҡ„ж•°жҚ®ж ·жң¬гҖӮеӣҫзүҮз”ұжүҚи®©е…ҲжңЁжҸҗдҫӣгҖӮ
гҖҖгҖҖд»Җд№ҲжҳҜMNISTпјҹ
еӣҫдёәMNIST ж•°жҚ®йӣҶгҖӮеӣҫзүҮз”ұжүҚи®©е…ҲжңЁжҸҗдҫӣгҖӮ
гҖҖгҖҖMNISTж•°жҚ®йӣҶз®ҖиҖҢиЁҖд№Ӣе°ұжҳҜдёҖдёӘжүӢеҶҷж•°жҚ®иҜҶеҲ«еә“пјҢеҢ…еҗ«жңүеӨ§йҮҸзҡ„жүӢеҶҷж•°еӯ—еӣҫеғҸпјҢеҸҜд»Ҙз”ЁжқҘиҜҶеҲ«еҗ„з§ҚжүӢеҶҷдҪ“ж•°еӯ—гҖӮMNIST ж•°жҚ®йӣҶжқҘиҮӘзҫҺеӣҪеӣҪ家ж ҮеҮҶдёҺжҠҖжңҜз ”з©¶жүҖ, з”ұYann LeCunж•ҷжҺҲдё»еҜје»әз«ӢгҖӮиҜҘж•°жҚ®йӣҶз”ұ250дёӘдёҚеҗҢдәәжүӢеҶҷзҡ„ж•°еӯ—жһ„жҲҗ, иҝҷ250дёӘдәәдёӯ50% жҳҜй«ҳдёӯеӯҰз”ҹ, 50% жқҘиҮӘдәәеҸЈжҷ®жҹҘеұҖзҡ„е·ҘдҪңдәәе‘ҳгҖӮиҜҘж•°жҚ®йӣҶе…ұеҢ…еҗ«70000еј ж•°еӯ—еӣҫеғҸпјҢе…¶дёӯи®ӯз»ғйӣҶ60000еј пјҢжөӢиҜ•йӣҶ10000еј гҖӮиҮӘMNISTж•°жҚ®йӣҶе»әз«Ӣд»ҘжқҘпјҢиў«е№ҝжіӣең°еә”з”ЁдәҺжЈҖйӘҢеҗ„з§ҚжңәеҷЁеӯҰд№ з®—жі•пјҢжөӢиҜ•еҗ„з§ҚжЁЎеһӢпјҢдёәжңәеҷЁеӯҰд№ зҡ„еҸ‘еұ•еҒҡеҮәдәҶдёҚеҸҜзЈЁзҒӯзҡ„иҙЎзҢ®гҖӮ
гҖҖгҖҖз”Ёе®ғеҒҡд»Җд№Ҳпјҹ
гҖҖгҖҖжҚ®еӣўйҳҹиҙҹиҙЈдәәиўҒжҳҺеҘҮеҗҢеӯҰд»Ӣз»ҚпјҢзҺ°еңЁеҫҲеӨҡдәәйғҪз”ЁиҝҮи§ҰеұҸжқҝжүӢжңәжҲ–з”өи„‘зҡ„жүӢеҶҷеҠҹиғҪпјҢжҜҸдёӘдәәйғҪжңүиҮӘе·ұзҡ„д№ҰеҶҷйЈҺж јпјҢйӮЈд№ҲеҪ“жҲ‘们еҶҷдёӢж•°еӯ—д№ӢеҗҺпјҢеҰӮдҪ•и®©и®Ўз®—жңәжҲҗеҠҹең°иҜҶеҲ«е‘ўпјҢжҲ‘们еҸҜд»ҘйҖҡиҝҮжңәеҷЁеӯҰд№ зҡ„ж–№жі•жқҘи§ЈеҶіиҝҷдёӘй—®йўҳпјҢеҰӮдҪҝз”ЁеҚ·з§ҜзҘһз»ҸзҪ‘з»ңжЁЎеһӢпјҢжЁЎеһӢзҡ„з»“жһ„еҰӮдёӢжүҖзӨәпјҡ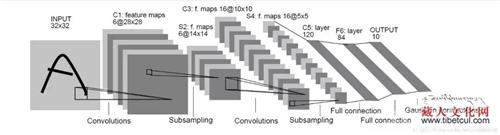
еӣҫдёәLeNet5еҚ·з§ҜзҘһз»ҸзҪ‘з»ңжЁЎеһӢз»“жһ„гҖӮ еӣҫзүҮз”ұжүҚи®©е…ҲжңЁжҸҗдҫӣгҖӮ
гҖҖгҖҖйҖҡиҝҮиҫ“е…ҘMNISTж•°жҚ®еҜ№жЁЎеһӢиҝӣиЎҢи®ӯз»ғпјҢжңҖз»ҲдјҡиҺ·еҫ—дёҖдёӘеҸҜиҜҶеҲ«жүӢеҶҷдҪ“ж•°еӯ—зҡ„зҪ‘з»ңжЁЎеһӢпјҢиҝҷе°ұдёәи®Ўз®—жңәиҜҶеҲ«жүӢеҶҷдҪ“ж•°еӯ—жҸҗдҫӣдәҶдёҖз§ҚеҫҲжЈ’зҡ„ж–№жі•гҖӮMNISTж•°жҚ®йӣҶзҡ„з”ҹе‘ҪеҠӣжһҒе…¶ж—әзӣӣпјҢиҮӘе…¶е»әз«Ӣд»ҘжқҘпјҢеңЁе…¶еҹәзЎҖдёҠиЎҚз”ҹеҮәдәҶжӣҙеӨҡзҡ„еҸҳејҸпјҢеҰӮFashionMNISTпјҢе®ғ们йғҪз»ҷеҮәдәҶдёҚдҝ—зҡ„иЎЁзҺ°гҖӮ
гҖҖгҖҖе°Ҷж°‘ж—Ҹж–ҮеҢ–иһҚе…ҘжңәеҷЁеӯҰд№
гҖҖгҖҖ“еңЁдёҖж¬Ўдјҡи®®дёҠпјҢжҲ‘ж— ж„Ҹй—ҙзңӢеҲ°дәҶдёҖдҪҚи—Ҹж—Ҹдјҷдјҙзҡ„笔记жң¬дёҠеҶҷзқҖдёҖдәӣеҘҮзү№зҡ„з¬ҰеҸ·гҖӮд»–е‘ҠиҜүжҲ‘пјҢиҝҷдәӣжҳҜи—Ҹж–Үж•°еӯ—пјҢиҝҷеҜ№дәҺд»Һе°ҸдҪҝз”ЁйҳҝжӢүдјҜж•°еӯ—зҡ„жҲ‘еҚҒеҲҶжғҠ讶пјҢиҝҷдәӣеҘҮзү№зҡ„з¬ҰеҸ·з«ҹжңүеҰӮжӯӨзү№ж®Ҡзҡ„еҗ«д№үпјҒжҲ‘еҪ“ж—¶е°ұдә§з”ҹдәҶдёҖдёӘжғіжі•пјҢиғҪдёҚиғҪи®©и®Ўз®—жңәд№ҹиғҪиҜҶеҲ«иҝҷдәӣж•°еӯ—е‘ўпјҹ”иўҒжҳҺеҘҮе‘ҠиҜүи®°иҖ…пјҢ“еҪ“ж—¶жғіжі•еҫҲз®ҖеҚ•пјҢе°ұжҳҜеёҢжңӣе°Ҷе°‘ж•°ж°‘ж—Ҹж–ҮеҢ–иһҚе…ҘеҲ°жңәеҷЁеӯҰд№ дёӯгҖӮ”
гҖҖгҖҖ“иҝҷдёӘжғіжі•еҫ—еҲ°дәҶеӨ§е®¶зҡ„дёҖиҮҙи®ӨеҸҜпјҢдәҺжҳҜжҲ‘们ејҖе§ӢжЁЎд»ҝMNISTжқҘеҲ¶дҪңиҝҷдәӣж•°жҚ®пјҢз”ұдәҺеҜ№и—Ҹж–Үзҡ„дёҚзҶҹжӮүпјҢдёҖејҖе§Ӣзҡ„е·ҘдҪңеҚҒеҲҶиү°йҡҫпјҢзӣҙеҲ°еҸ–еҫ—дәҶи—ҸеӯҰз ”з©¶йҷўеҗҢеӯҰзҡ„её®еҠ©пјҢжүҚдҪҝеҫ—еҲ¶дҪңе·ҘдҪңйЎәеҲ©е®ҢжҲҗгҖӮеҺҶж—¶1дёӘжңҲпјҢи¶…иҝҮ300ж¬ЎеҸҚеӨҚзӯӣйҖүпјҢжңҖз»Ҳеҫ—еҲ°17768еј й«ҳжё…и—Ҹж–ҮжүӢеҶҷдҪ“ж•°еӯ—еӣҫеғҸпјҢеҪўжҲҗдәҶTibetanMNISTж•°жҚ®йӣҶгҖӮ”и°Ҳиө·йӮЈдёҖдёӘжңҲзҡ„е·ҘдҪңпјҢеӣўйҳҹжҲҗе‘ҳзә·зә·иЎЁзӨә“зҙҜ并еҝ«д№җзқҖ”гҖӮ
гҖҖгҖҖи—Ҹж–ҮдҪңдёәжҲ‘еӣҪзҡ„е°‘ж•°ж°‘ж—Ҹж–Үеӯ—д№ӢдёҖпјҢе…·жңүеҚҒеҲҶжӮ д№…зҡ„ж–ҮеҢ–еҺҶеҸІпјҢиҖҢи—Ҹж–Үж–Үеӯ—зӢ¬зү№зҡ„д№ҰеҶҷж–№ејҸе’Ңжһ„йҖ пјҢдҪҝеҫ—е…¶жһҒе…·зҫҺж„ҹпјҒи—Ҹж–Үдё»иҰҒжңүжҘ·дҪ“е’ҢиЎҢдҪ“дёӨз§Қд№Ұжі•дҪ“пјҢжӯӨж¬ЎеҲӣж–°еӣўйҳҹеҲ¶дҪңзҡ„TibetanMNISTжӯЈжҳҜиЎҢдҪ“и—Ҹж–Үдёӯзҡ„ж•°еӯ—пјҢеҰӮдёӢеӣҫжүҖзӨәпјҡ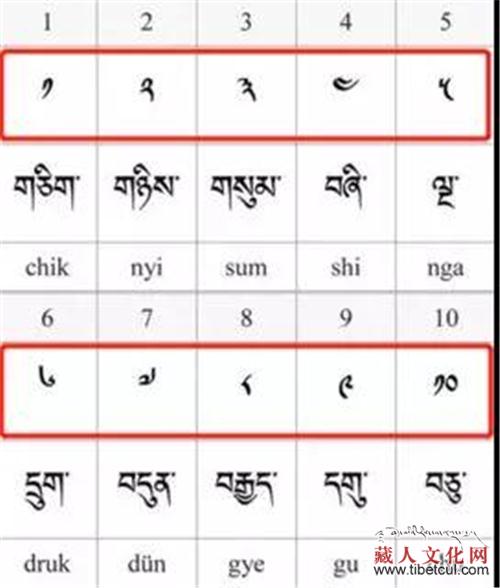
еӣҫдёәеҪўдҪ“и—Ҹж–ҮгҖҒжҘ·дҪ“и—Ҹж–ҮгҖҒжӢүдёҒж–Үд»ҘеҸҠйҳҝжӢүдјҜж•°еӯ—зҡ„еҜ№з…§иЎЁгҖӮеӣҫзүҮз”ұжүҚи®©е…ҲжңЁжҸҗдҫӣгҖӮ
гҖҖгҖҖдёҚеҝҳеҲқеҝғпјҢејҖжәҗе…ұдә«
гҖҖгҖҖ“жҲ‘们д№ҹжІЎжңүжғіеҲ°иҝҷдёӘйЎ№зӣ®дјҡжңүйӮЈд№ҲеӨҡдәәе…іжіЁпјҢзҺ°еңЁжңүеҫҲеӨҡдәәи·ҹжҲ‘们иҒ”зі»пјҢиЎЁзӨәеҜ№иҝҷдёӘйЎ№зӣ®ж„ҹе…ҙи¶ЈгҖӮ”иўҒжҳҺеҘҮеҜ№иҮӘе·ұеӣўйҳҹеҸ–еҫ—зҡ„е·ҘдҪңжҲҗжһңж„ҹеҲ°йӘ„еӮІгҖӮ“дҪҶжҳҜпјҢиҝҷеҸӘжҳҜдёҮйҮҢй•ҝеҫҒ第дёҖжӯҘпјҢжҲ‘们йңҖиҰҒжӣҙеӨҡзҡ„еӣҫеғҸж•°жҚ®пјҢдёҚж–ӯеҜ№з®—жі•иҝӣиЎҢдјҳеҢ–пјҢжүҚиғҪдҝқиҜҒиҝҷдёӘиҜҶеҲ«жЁЎеһӢзҡ„зІҫеҜҶзЁӢеәҰгҖӮиҖҢдё”пјҢзҺ°еңЁеҸӘжҳҜи—Ҹж–Үж•°еӯ—ж•°жҚ®йӣҶж–№йқўжңүдәҶиҝӣеұ•пјҢеҗҺжңҹжҲ‘们иҝҳиҰҒеҒҡи—Ҹж–Үеӯ—жҜҚжүӢеҶҷдҪ“ж•°жҚ®йӣҶзӯүдёҖзі»еҲ—жӣҙеҠ еӨҚжқӮзҡ„ж•°жҚ®гҖӮи·қзҰ»е®һйҷ…зҡ„еә”з”Ёйҳ¶ж®өпјҢжҲ‘们иҝҳжңүеҫҲеӨҡе·ҘдҪңиҰҒеҒҡгҖӮ”
еӣҫдёәеӣўйҳҹдё»иҰҒиҙҹиҙЈдәәеңЁи°·жӯҢејҖеҸ‘иҖ…зӨҫеҢәжҙ»еҠЁзҺ°еңәгҖӮеӣҫзүҮз”ұжүҚи®©е…ҲжңЁжҸҗдҫӣгҖӮ
гҖҖгҖҖйқўеҜ№зӘҒеҰӮе…¶жқҘзҡ„е…іжіЁпјҢиҝҷзҫӨиә«жҖҖдәәе·ҘжҷәиғҪжўҰжғізҡ„95еҗҺеӯҰз”ҹеӣўйҳҹпјҢеҒҡеҮәдәҶдёҖдёӘи®©дәәжғҠеҸ№зҡ„дёҫеҠЁпјҢ“жҲ‘们并没жңүжғіиҝҮеҲ©з”ЁиҝҷдёӘйЎ№зӣ®жҢЈй’ұпјҢиҝҷдёҚжҳҜжҲ‘们зҡ„еҲқиЎ·пјҢжүҖд»Ҙз»ҸиҝҮеҸҚеӨҚе•Ҷи®®пјҢжҲ‘们еҶіе®ҡе°Ҷе…¶е®Ңе…ЁејҖжәҗпјҢдҫӣжүҖжңүзҡ„ејҖеҸ‘иҖ…иҮӘз”ұдҪҝз”ЁпјҢиҝҷж ·жүҚиғҪдҪҝе…¶иғҪеҸ‘жҢҘжңҖеӨ§зҡ„д»·еҖјпјҒ”





















